此博客主要内容为 《 Scala 程序设计 (第 2 版) 》 读书笔记,转载请保留原始地址。 需要更加深入学习建议购买正版图书 图灵社区
快速入门
用 scala 简洁有效的完成工作
分号
Scala 可以省略分号,多个表达式处于一行时用分号分隔。
变量声明
val声明不可变变量var声明可变变量
可变与不可变是指引用是否可变,不是引用指向的堆内存是否可变,注意不要与 scala 的 immutable 与 mutable 搞混淆,例如:
val array: Array[String] = new Array(5)
array(0) = "hello" //可以正确运行
array = new Array(2) //不可以正确运行
用 val 与 var 声明变量必须初始化,当 val 与 var 用于类的构造函数的参数中的时候,这时候变量是类的一个属性。 val 属性不可变, var 属性可变。为了减少可变性引起的 bug ,应该尽可能少使用 var 。
偏函数
val pf: PartialFunction[String, String] = {
case "one" => "ONE"
case "two" => "TWO"
}
示例代码中 pf 的类型是 String => String ,但是真实的函数 pf 只能处理 “one” 和 “two” 两种输入,除此之外的任何字符串都不能处理,函数 pf 就是一个偏函数,偏函数只能处理与 case 匹配的输入参数。如果偏函数被调用,而函数的输入与所有的语句都不匹配,系统会抛出 MatchError 运行时错误。可以使用 isDefineAt 方法测试输入参数是否与偏函数匹配。
偏函数可以链式链接, pf1 orElse pf2 orElse pf3 ... , 如果 pf1 不匹配 , 就会尝试 pf2 ,以此类推, 都不匹配才会抛出 MatchError 。
方法声明
命名参数列表
case class Point(x: Double = 0.0, y: Double = 0.0) {
def shift(deltax: Double = 0.0, deltay: Double = 0.0) =
copy (x + deltax, y + deltay)
}
可行的构造方式有:
val p = new Point(x=3.0, y=4.0)
val p1 = Point(3.0,4.0)
val p2 = Point(3.0) //p2 = Point(3.0, 0.0)
val p3 = Point(y=4.0) //p3 = Point(0.0, 4.0)
多个参数列表
def drawPoint(p: Point = Point(0.0, 0.0))(drawfunc: String => Unit = println) =
drawfunc(p.toString)
可以任意指定参数列表的个数, 但是实际上很少有人使用两个以上的参数列表。当最后一个参数列表包含一个表示函数的参数时, 多个参数列表的形式拥有整齐的块结构语法, 还允许将参数列表两边的圆括号替换为花括号, 例如:
drawPoint(Point(3.0, 4.0)) {
str => {
println("drawfunc !!!")
println(str) //{...} 代码快的返回值为最后一个表达式的值,在这儿就是 println(str)
}
}
这种方式很像其他语言中的 if 和 for 表达式, 只不过在 scala 的这种写法中, {...} 块表示的是传给 drawPoint 方法的参数, str => {...}其本质是一个类型为 String => Unit 的匿名函数。 示例代码中第一个参数使用默认值时第一个括号不能省略。
多参数列表第二个优势是类型推断:
def m1[A](a: A, f: A => String) = f(a)
def m2[A](a: A)(f: A => String) = f(a)
m1(100, i => i.toString) //error: missing parameter type
m2(100)(i => i.toString) //可以正常运行
多参数列表第三个优势是最后一个参数列表使用 implicit 关键字声明隐式参数,当相应方法被调用时,可以显示指定这个参数,当没有指定时,编译器会在当前作用域找到一个合适的值作为参数,可以让代码更精简。下节的 Future 就是这样一个例子。
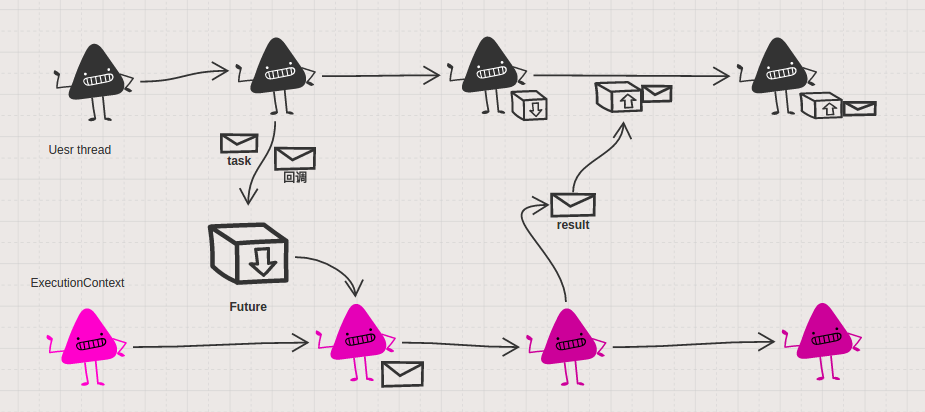
Future 简介
object Future {
def apply[T](body: => T)(implicit execctx: ExecutionContext): Future[T]
}
Future 将一段耗时的代码 body 进行封装,封装后返回一个 Future[T] 类型的对象,这段代码会在 ExecutionContext 中进行执行,只有在 ExecutionContext 中执行结束, Future[T] 类型的对象才能获取到 body 的运行结果。 示例代码中的 body 为 传名参数 , 后文会有详细介绍。 更多关于 Future 的介绍可以 点击 进行更多了解。
嵌套方法与递归
方法的定义可以嵌套,方法内部可以定义方法,但是内部方法只有在方法内部可见, 下面示例方法 fact 与 factTail 就是方法 factorial 的内部方法,在 factorial 外部不可见:
def factorial(i: Int): Long = {
def fact(n: Int): Long = {
case 1 => 1.toLong
case n if n > 1 => n * f(n - 1)
}
def factTail(n: Int, acc: Long): Long = {
n match {
case 1 => 1.toLong
case n if n > 1 => factTail(n - 1, n * acc )
}
}
fact(i)
}
在示例中, fact 与 factTail 都调用了本身, 像这种方式定义的方法就是递归方法。
尾递归
在上一节的示例中, fact 与 factTail 都是递归方法, 但是他们有点不同,这是一种使用递归的诡计, 让我们先从函数栈的角度来理解递归,然后再画一个简单的示意图来理解这种诡计。 要理解尾递归,先要理解函数调用栈。
Java 栈是一块线程私有的内存空间。 java 堆和程序数据相关, java 栈就是和线程执行密切相关的,线程的执行的基本行为是函数调用,每次函数调用的数据都是通过 java 栈来传递的。 Java 栈与数据结构中的 stack 有着类似的含义,都是先进先出的数据结构,只支持出栈和入栈操作。 java 栈中保存的主要内容为栈帧。每一次函数调用都有一个对应的栈帧被压入 java 栈。 每一个函数调用结束,都会有一个栈帧被弹出 java 栈。当前正在执行的函所对应的栈帧位于当前栈的栈顶,它保存当前函数的局部变量,中间运算结果等数据。
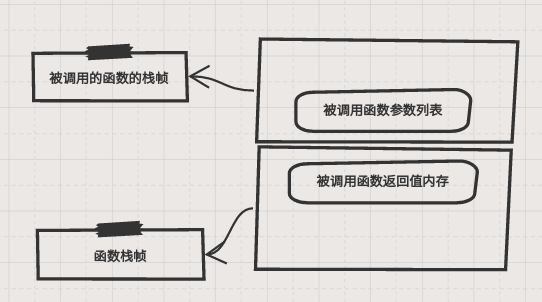
在示意图中,被调用函数执行结束后相应的栈帧就会被弹出,执行的结果放在调用函数栈帧的某个位置。 了解了函数栈帧后再来看递归函数,因为递归函数的参数在没有到达边界条件的时候,比如上节示例代码中 fact 参数大于 1 的时候, fact 就会一直调用自身, 相应的栈帧就会一直增长, 如果栈空间不足, 就会造成 StackOverflowError 错误。 这是使用递归函数需要非常小心的地方!
而尾递归是编译器对递归的一种优化措施(将递归编译成等效的循环), 但并不是所有的递归函数都可以进行尾递归优化, 书本中这样定义尾递归: 表示调用递归函数是该函数中最后一个表达式,该表达式的返回值就是所调用的递归函数的返回值 。 下面我们结合一些简单的示意图来理解这个定义:
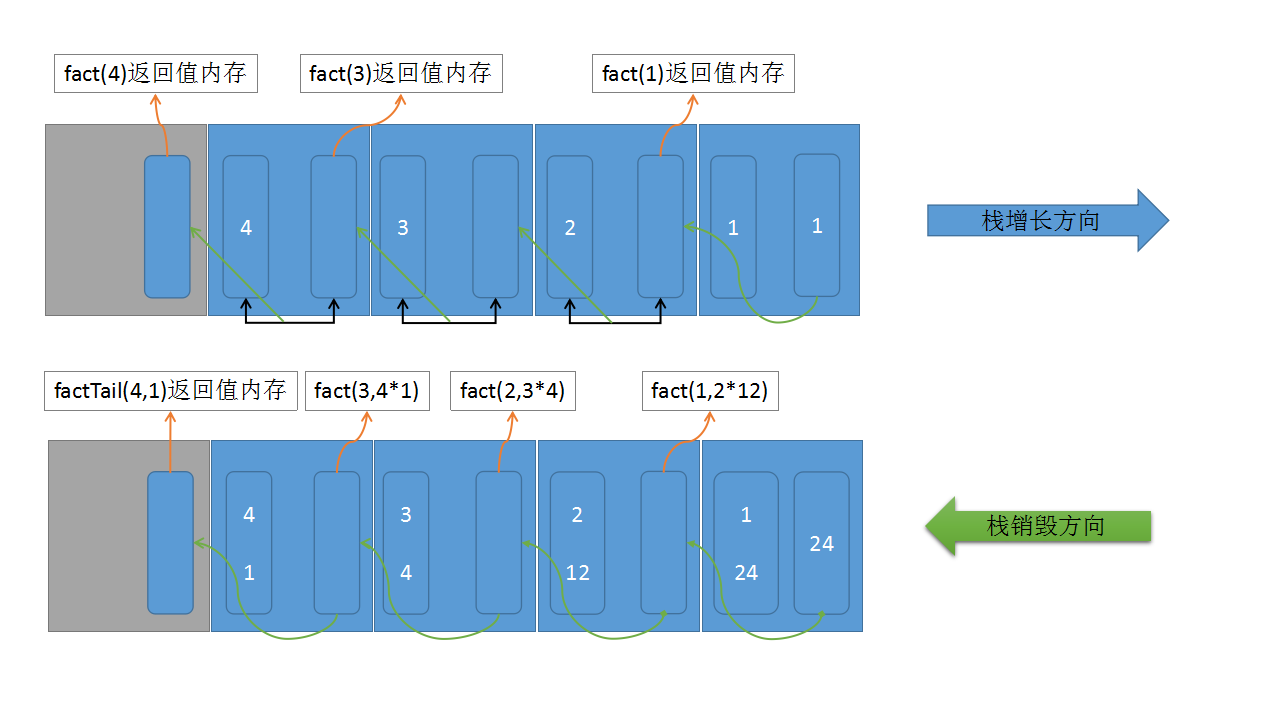
先对上图做一点简单的说明,灰色的块表示调用递归方法的栈帧, 蓝色的块表示递归方法的栈帧, 这个简图只是为了形象的描述递归方法,不一定完全满足真实的栈帧布局,欲了解详细情况请学习 JVM 相关知识! 绿色的线表示栈帧销毁的方向, 栈增长的时候必要的信息向新生的栈帧中传递,一般栈增长时传递的信息表现为递归函数的参数, 而栈帧销毁的时候代表了信息的反向传递,在 fact 这种情况中, 前一个栈帧运行结束, 返回值会和当前栈帧其他的存储在内存中的值做运算,以运算结果作为当前栈帧的返回值, 然后再销毁当前栈帧, 图中上半部分的情况描述了这一过程, 在这种情况中, 一个栈帧的返回值依赖于上一个栈帧的返回值和当前栈帧中的一些信息。 在 factTail 这种情况中,前一个栈帧运行结束, 返回值不与当前栈帧中的信息发生运算, 直接将前一个栈帧的返回值作为当前栈帧的返回值, 相当于最终的结果在栈生长到最后一个栈帧的时候就已经确定了, 栈帧销毁的时候只是把这个固定的信息向栈帧销毁的方向移动, 每个栈帧之前保存的信息对于最终的信息没有任何影响!
基于上诉分析,我们发现图例中下面这种情况可以做一种优化: 既然栈帧生成的时候就已经确定了最终的信息,那么栈帧销毁就没有必要了, 我们可以省略掉这个反向的过程! 但是函数调用必须要一个一个栈帧的销毁, 不能进行跳跃式的销毁, 所以我们有必要对这个过程做进一步的分析, 既然栈帧生成的时候就确定了最终的信息,也就是说最终的信息只与栈帧生成时传递的信息有关, 而栈帧每次传递的信息只有参数,而参数的数量是固定的, 并且生成下一个栈帧后这些参数就不会被使用了, 那么我们可以不再生成新的栈帧了, 直接把新的参数覆盖掉当前的参数, 对于 factTail 的例子就是在 [4 1] 的位置重新换上新的参数 [3 4] , 而这就是循环: 一个位置控制结束,一个位置保存当前结果,每次循环更新控制状态、更新当前结果! scala 中在方法定义前使用 @tailrec 注解可以提醒编译器检查是否满足尾递归并对尾递归进行优化。
类型推断
scala 是一个静态类型的语言, 但是 scala 的编译器又提供了一定能力的类型推断功能, 降低了代码的冗余度, 一些函数式编程语言, 如 Haskell , 可以推断出几乎所有的类型, 因为他们可以执行全局类型推断。 但是 scala 因为支持了继承,使得全局推断困难得多。 下面这些情况需要显式的指明类型信息:
- 用
var或val声明没有初始化的变量, 比如在类的抽象声明中val book: String。 - 所有的方法参数, 如
def deposit(amount: Money) = {...} - 方法的返回值类型, 在以下情况中必须显示声明类型:
- 在方法中明显使用了
return。 - 递归方法
- 两个或多个方法重载, 其中一个方法调用了另一个重载方法, 调用者需要显示类型注解。
- Scala 推断出的类型比你期望的更加宽泛。
- 在方法中明显使用了
object StringUtil {
def joiner(string: String*): String = string.mkString("-")
def joiner(string: List[String]) =
joiner(string :_*) //不能通过编译,需要显式指明方法返回类型
def makeList(strings: String*) = {//期望类型推断为 List[String]
if (strings.length == 0)
List(0) //误用,类型为 List[Int],本来该用 List.empty[String]
else strings.toList //类型为 List[String]
} //类型将会被推断为 List[Any]
def double(i: Int) { 2 * i} //类型推断为 Unit
def double2(i: Int) = { 2 * i} //类型推断为 Int
}
字面量
- 整数
- 十进制:
0或 非0开头的数字 - 十六进制:
0x+(0-9, A-F or a-f) - 八进制:
0+ 数字, 从 scala 2.10 已经废弃
- 十进制:
- 浮点
Float小数后加f或者FDouble小数后加d或者D, 小数后不加默认Double- 小数点后没有数字的浮点数例如
3.这种写法在scala 2.10中废弃, 在scala 2.11中禁止!
- 布尔: 类型为
Boolean, 只有两个值truefalse
- 字符
- 字符串
- 双引号: 里面出现双引号需要转义字符
\ - 三重引号: 可以跨行, 可以包含任意字符, 不会转义, 但是里面不能出现三个连续的引号
- 双引号: 里面出现双引号需要转义字符
def hello(name: String) = s"""Welcome !
Hello, $name !
* (Gratuitous Star !)
|We're glad you're here.
| Have some extra whitespace.""".stripMargin()
hello("yankun")
输出:
Welcome !
Hello, yankun !
* (Gratuitous Star !)
We're glad you're here.
Have some extra whitespace
- 符号:
'+数字or字母or下划线, 但是第一个字符不能为数字, 或者Symbol("id"), 包含空格的符号Symbol("id ") - 函数:
val f: (Int, String) => String = (i, s) => s + i.toString(), 对象f的类型为Function2[Int. String, String](简写为(Int, String) => String) - 元组:
TupleN, 例如val tup = ("www.yankun.tech", 100)类型为Tuple2[String, Int]简写为(String, Int)。 使用_n从元组中提取值, 例如tup._1。 使用箭头操作符产生二元组"www.yankun.tech" -> 100。
值、对象、类、类型
- 值与对象会在内存中占用一块内存, 一定意义上说, 值与对象是个等效的概念。
- 伴生对象: 一个与类同名称的对象, 比如
List对象。 这种对象里含有一个方法apply, 当任意一个对象包含这个方法的时候, 调用这个方法可以不用写成对象.apply(参数)可以简写为对象(参数)。 比如List的apply方法, 调用时直接使用List(参数),List对象apply方法类型签名为:def apply[T](args: T*): List[T] = {...} - 单例对象: 用
object关键字定义的一个单独的对象。 - 函数对象: 在 scala 中, 函数与方法是不同的, 函数是一个对象, 就跟字符串对象或者其他对象是一样概念的对象, 之所以我们可以使用
函数(参数)是因为函数对象里面有一个apply方法, 通过上文我们知道函数(参数)是函数.apply(参数)的简写。 而方法是对象的一个字段, 跟一般的方法概念是一样的, 但是我们可以把方法变成一个函数对象, 方法提升为函数对象的方式一般有两种:- 部分应用: 调用方法, 有些参数有值,有点参数没有值,没有值的使用下划线占位, 将会产生一个以下划线为参数列表的函数。
eta变换:方法 _
- 伴生对象: 一个与类同名称的对象, 比如
- 类是构造对象的模板。 一个类可能有多个类型, 比如类
Array[T]的实际类型有Array[String]、Array[Int]等。- 伴生类: 与对象同名称的类。
传名参数、传值参数
- 传值参数: 通常所见的参数类型, 参数是一个值, 调用方法的时候需要先计算出参数的值,再进入方法内部执行。
- 普通值: 普通的值与对象。
- 函数对象: 参数为一个函数对象, 比如
def test(code : ()=>Unit): Unit
- 传名参数: 参数为一个代码块, 调用方法时不对代码块进行求值, 方法内部每次使用该参数都对参数进行一次求值。 例如:
def test1(code: ()=>Unit){ //参数为传值参数(一个函数对象) println("start") code() //其实是调用 code 对象的 apply 方法 println("end") code() } test1 {//此代码块, 先对代码块求值(代码块的值为最后一个表达式的值), 再进入方法, 方法内部可以直接使用这个值 println("1111") ()=>{println("2222")} }执行结果为:
1111 start 2222 end 2222def test(code : => Unit){ //传名参数 println("start") code // 可以理解为直接展开代码块, 然后对代码块求值, 每次使用都是这个过程, 也可以写成 code() println("end") code } test{// 不对代码块求值, 作为一个整体进入方法 println("1111") println("2222") }执行结果为:
start 1111 2222 end 1111 2222使用传名参数可以很容易定义一些看起来就像语言本身支持的一些特性, 比如定义我们自己的条件循环:
@annotation.tailrec // <1> def continue(conditional: => Boolean)(body: => Unit) { // <2> if (conditional) { // <3> body // <4> continue(conditional)(body) } } var count = 0 // <5> continue(count < 5) { println(s"at $count") count += 1 }
Option 、 Some 和 None : 避免使用 null
当一个返回值可能产生 null 的时候, 不直接返回这个值, 而是使用 Option[T] 对象对返回值进行封装, 正常值为 Some(value of type T) , null 变为 None , Some 与 None 都是 Option[T] 的子类, 对 Option[T] 对象使用 get 方法获取 Option[T] 里的值, 如果是 None 将会抛出 NoSuchElementException 异常。 可以使用更安全的 getOrElse 方法为 None 提供一个默认值。 更多知识可以点击 这里 了解。
封闭类的继承
使用关键字 sealed 告诉编译器所有子类必须在同一个源文件中声明。 比如类型 Option 只有两个子类 Some 和 None, 为了防止用户私自给 Option 派生其他子类, Option 声明时使用 sealed 关键字进行限制:
sealed abstract class Option[+T] extends ... {...}
代码组织:文件和名空间
Scala 沿用 Java 用包涞表示命名空间这一做法, 但是更加灵活, 文件名不必与类名一致, 包结构不一定要与目录结构一致。
- Java 常规写法:
//file: src/main/com/example/mypkg.scala package com.example.mypkg class MyClass {...} - 嵌套结构语法定义包作用域
//file: src/main/com/example/mypkg.scala package com { package example{ package pkg1{ class C11 {def m = "m11"} class C12 {def m = "m12"} } package pkg2{ class C21 {def m = "m21"; def makeC11 = {new pkg1.C11}; } } package pkg3.pkg31.pkg311 { class C311 {def m = "m311"} } } } - 包不能在类或对象中定义
导入类型及成员
import java.awt._ //导入 awt 下所有成员
import java.io.File //导入 File
import java.util.{Map, HashMap} //导入 Map HashMap
import java.math.BigInteger.{
ONE => _ , //隐藏这个成员
TEN , //导入 TEN
ZERO => JAVAZERO //导入 ZERO 并重命名为 JAVAZERO
}
导入是相对的
import collection.immutable._
// collection 为 scala 包的子包, scala 包默认已导入
import _root_.scala.collection.parallel._ //从根开始导入
包对象
// src/com/example/json/package.scala //文件名必须为 package.scala
package com.example //json 包的上层包作用域
package object json { //package 关键字给包对象命名, 此处为 json
class JSONObject {...} //暴露给 API 使用者的包对象的成员
def formString(string: String): JSONObject = {...}
}
使用时通过 import com.example.json._ 导入包对象中的成员
抽象类型与参数化类型
参数化类型
Scala 中参数化类型类似于 java 中的泛型, 但是比 java 泛型更加强大。 在 java 中使用 <..> 代表泛型, 在 scala 中使用 [..] 代表参数化类型, 因为 scala 中 < 与 > 常用作方法名。 比如字符串可以声明为:
val strings = List[String] = List("one", "two", "three")
从 [列表标准库] 中可以看见其声明为:
sealed abstract class List[+T] extends ... {...}
此处的 T 就是 List 的类型参数。
类型参数有三种变性:
- 协变: 声明为
C[+T], 如果B是A的子类型, 那么C[B]自动为C[A]的子类型。 - 逆变: 声明为
C[-T], 如果B是A的子类型, 那么C[A]自动为C[B]的子类型。 - 不变: 声明为
C[T], 如果B是A的子类型,C[A]与C[B]没有父子关系。
抽象类型
抽象类型与参数化类型有所重合, 但不冗余, 两种机制对不同的问题各有优势与不足。 抽象类型使用 type 关键字声明一个抽象类型作为其他类型的成员, 子类化的时候将抽象类型具体化:
import java.io._
abstract class BulkReader {
type In
val source: In
def read: String
}
class StringBulkReader(val source: String) extends BulkReader {
type In = String
def read: String = source
}
class FileBulkReader(val source: File) extends BulkReader {
type In = File
def read: String = {
val in = new BufferedInputStream(new FileInputStream(source))
val numBytes = in.available()
val bytes = new Array[Byte](numBytes)
in.read(bytes, 0, numBytes)
new String(bytes)
}
}
println(new StringBulkReader("hello scala !").read)
println(new FileBulkReader(new File("path/to/some/file")).read)
如果改为参数化类型的协法为:
abstract class BulkReader[In] {
val source: In
...
}
class StringBulkReader(val source: String) extends BulkReader[String] {...}
class FileBulkReader(val source: File) extends BulkReader[File] {...}
类型成员相比参数化类型的优势
- 当类型参数与参数化的类型无关时, 参数化类型更加适用。 比如
List[T],T可以是Int或者String等。 - 而当类型成员与所封装的类型同步变化时, 类型成员更加适用。 比如
BulkReader这个例子, 类型成员需要与封装的类型行为一致。 有时这种特点被称为家族多态, 或者协特化。
要点详解
操作符
在 scala 中, java 那些基本类型全都变成了正规的对象, 比如 Float、 Double 等, 这也意味着他们都有成员方法。 scala 中所有的操作符都是方法, 单参数方法可以使用中缀表达式, 比如 1.+(2) 可以用中缀表达式写为 1 + 2.
实际上根据优先级规则, 包含点与身=省去点并不是完全一致的,
1 + 2 * 3与1.+(2).*(3)是不一样的。 如果表达式中包含点号, 那么点号具有最高优先级。
类似的调用无参方法可以省略点号, 这种方法称之为后缀表达式, 不过后缀表达式容易产生歧义。 直接使用会引发一个警告, 可以使用 import scala.language.postfixOps 开启这个特性去除警告。
无参数方法的括号
scala 允许用户灵活决定是否使用括号。
- 定义无参方法时省略了括号, 调用时也必须省略括号。
- 定义时添加了括号, 调用时可以选择是否保留括号。
注意以下写法的迷惑性, 思考一下为什么:
def f1 = () => println("hello")
def f2() = () => println("hello")
f1 //res0: () => println("hello")
f1() //hello
f2 //res1: () => println("hello")
f2() //res2: () => println("hello")
f2()() //hello
scala 社区的惯例是: 定义无副作用的无参方法时省略括号, 定义有副作用的方法添加括号。 运行 scala 添加
-Xlint对不满足这种惯例的写法发出警告。
这种中缀与后缀的写法结合类型推断可以使代码变得更加简洁, 如下着几种写法是等效的:
def isEven(n: Int) = (n % 2) == 0
List(1,2,3,4).filter((i: Int) => isEven(i)).foreach((i: Int) => println(i))
List(1,2,3,4).filter(i => isEven(i)).foreach(i => println(i))
List(1,2,3,4).filter(isEven).foreach(println)
List(1,2,3,4) filter isEven foreach println
需要注意的是这种写法每个方法都是接收的单一参数, 如果方法链中某一放啊接收 0 个或大于 1 个参数, 编译器就会困惑, 如果出现了这种情况, 请部分或全部补上点号。
优先级规则
- 优先级顺序, 由低到高:
所有字母|^&<>=!:+-*/%其他特殊字符
- 同优先级操作符重左到右结合
- 右结合: 任何名字以冒号
:结尾的方法都与右边的对象绑定。 比如::方法:val list = List(1,2,3) val l1 = 1 :: list //等效于 list.::(1) , 而不是 1.::(list)
领域特定语言 (DSL)
DSL 指专门为某一专门问题域编写的语言, 比如 SQL 就可以被视为一门 DSL 语言。 DSL 一般有两种类型:
- 内部 DSL : 嵌入到某一宿主语言内。
- 外部 DSL : 专门有一个定制的解析器负责解析。
scala 对这两种方式都有支持。 后面的章节会有详细的介绍。
if
表面上看, scala 的 if 语句 与 java 的相同, 但是 scala 中的 if 语句具有返回值, 在 scala 中几乎任何语句都是具有返回值的表达式。
scala 中 if 表达式的返回值是类型是所有分支条件的最小上界。
for 推导式
for 循环
类似于 java 中的 for 循环, 执行只会带来副作用:
val dogs = List("Bob", "Tom", "putty", "Kaiven")
for (dog <- dogs) println(dog)
表达式没有返回值。
生成器表达式
像上节 dog <- dogs 这样的表达式被称为 生成式器表达式 (generator expression), 操作符 <- 会对集合进行遍历。
保护式 (guard)
加入一个或多个 if 表达式进行更加细粒度的操作, 这种表达式被称为 保护式 (guard) , 在 Haskell 常被翻译为 守卫 :
for {
dog <- dogs
if dog.length > 3
// if dog.length < 8 // 可以加入多个
// if dog.length > 3 && dog.length <8 // 还可以这样写
} println(dog)
Yielding
使用 yield 在 for 推导式中生成新的集合。
val filterdog = for {
dog <- dogs
if dog.length > 3
if dog.length > 3 && dog.length < 8
} yield dog
// filterdog = List("putty", "Kaiven")
val maybedogs = List(Some("Bob"), None, Some("Tom"), None, Some("putty"))
val dogs2 = for {
dogoption <- maybedogs
dog <- dogoption
} yield {
dog
} //dog = List("Bob", "Tom", "putty")
for-yield 表达式生成的集合类型将根据被遍历集合推导而来。
其他循环结构
scala 中的 while
跟 java 中 while 类似。
scala 中的 do-while
跟 java 中 do-while 类似。
条件操作符
跟 java 中类似, 需要注意的是 && 是 || 短路操作, 一旦得知结果, 便会停止对表达式估值。 另外需要注意的是 == 和 != 在 scala 中是值比较, 跟 java 中 equals 等效, 而 java 中, == 和 != 是引用比较。 scala 中引用比较是方法 eq 。
try catch final
import scala.io.Source
import scala.util.control.NonFatal
object TryCatch {
def main(args: Array[String]): Unit = {
var source: Option[Source] = None
try {
source = Some(Source.fromFile(args(0)))
} catch {
case NonFatal(ex) => println(ex)
} finally {
for (s <- source) {
println("closing file ...")
s.close()
}
}
}
}
惰性赋值
惰性赋值是以延迟的方式初始化某值。 下面为一些需要用到该技术的常见场景:
- 表达式执行代价昂贵, 希望推迟操作, 直到需要表达式结果时才执行。
- 缩短模块启动时间。
- 为了确保对象中其他的字段初始化过程优先执行。
object ExpensiveRes{ lazy val resource: Int = init() def init(): Int = { // 执行某些代价高昂的操作 0 } }使用
lazy将执行过程推迟。 在对象第一次使用都是时候才进行初始化。
枚举
scala 没有使用语法来专门支持枚举, 而是使用标准库的 Enumeration 类。
object Breed extends Enumeration {
// type Breed = Value
val doberman = Value("Doberman Pinscher")
val yorkie = Value("Yorkshire Terrier")
val scottie = Value("Scottish Terrier")
val dane = Value("Great Dane")
val portie: Breed.Value = Value("Portuguese Water Dog")
}
// print a list of breeds and their IDs
println("ID\tBreed")
for (breed <- Breed.values) println(s"${breed.id}\t$breed")
通过调用 values 方法, 可以像集合那样处理枚举值, 每个枚举值的类型为 Breed.Value , Value 方法有几个重载版本:
- 接收单一参数: 如代码中示例
- 无参的
Value方法: 以对象名作为Value方法输入参数 - 接收 ID 值, 字符串默认为对象名
- 接收 ID 值, 字符串
在 scala 中枚举使用并不多, 多数情况可以通过使用 case 类替代, 但是 case 类比枚举更加重量。
可插入字符串
s前缀:s"fool ${expr}"expr为表达式: 对表达式求值, 对值调用toString方法后插入, 没有toString方法会报错。expr为字符串: 直接插入。- 要输入
$使用$$。
f前缀:val gross = 100f val net = 64f println(f"$$${gross}%.2f $$${net}%.2f") // 结果 "100.00 64.00"在深入学习
隐式转换后, 我们甚至可以定义自己的字符串插入器。
Trait初探: scala 中的接口和 “混入”
trait 是 scala 用来表示抽象的一个强大的武器, 很多高级的抽象都可以借助 trait 来实现。 在后面的章节会进行详细的讲解, 这儿只是对这一特性进行一些简单的介绍。 trait 可以使 scala 很容易实现组合这一抽象, 这种抽象比继承粒度更加小,更加精细, 可以很容易打破 java 对象模型的一些局限。
- 在
trait中可以声明示例字段, 并选择是否定义这些字段。 - 还可以声明或定义类型。
以下为一个使用 trait 混入日志的功能的一个示例:
class ServiceImportante(val name: String) {
def work(i: Int): Int = {
println(s"ServiceImportante: Doing important work! $i")
i + 1
}
}
val service1 = new ServiceImportante("uno")
(1 to 3) foreach (i => println(s"Result: ${service1.work(i)}"))
// BEGIN LOGGING
trait Logging {
def info (message: String): Unit
def warning(message: String): Unit
def error (message: String): Unit
}
trait StdoutLogging extends Logging {
def info (message: String) = println(s"INFO: $message")
def warning(message: String) = println(s"WARNING: $message")
def error (message: String) = println(s"ERROR: $message")
}
// END LOGGING
// BEGIN MIXED
val service2 = new ServiceImportante("dos") with StdoutLogging {
override def work(i: Int): Int = {
info(s"Starting work: i = $i")
val result = super.work(i)
info(s"Ending work: i = $i, result = $result")
result
}
}
(1 to 3) foreach (i => println(s"Result: ${service2.work(i)}"))
new ServiceImportante("dos") with StdoutLogging {...} 的方式其实是匿名类, 如果想多次使用这个类, 可以实际声明一个类:
class LoggedServiceImportante(name: String)
extends ServiceImportante(name) with StdoutLogging {...}
可以使用 with 混入多个特质。
模式匹配
在 C 、 java 等语言中有 case 语句用来匹配表达式的值, 在 scala 中, 这一功能被大大的扩展, 不仅可以匹配表达式的值, 还可以匹配类型、通配符、序列、正则表达式, 甚至可以获取对象内部的状态, 这种对象内部的状态的获取循序一定的协议, 对象内部可见性由该类型的实现控制。 对象状态的获取一般称为 提取 或 解构 。 scala 的 match 语句中, 匹配值会按照 case 语句的先后顺序进行匹配, 一旦匹配成功就结束匹配, 不用 break 手动结束匹配。
简单匹配
匹配一些简单的值, 跟 java 中类似:
val bools = Seq(true, false)
for (bool <- bools) {
bool match {
case true => println("Got heads")
case false => println("Got tails")
}
}
match 中的值、 变量和类型
case 语句可以是一个带类型标注的变量, 匹配成功后值会赋给对应的变量:
for {
x <- Seq(1, 2, 2.7, "one", "two", 'four) // <1>
} {
val str = x match { // <2>
case 1 => "int 1" // <3>
case i: Int => "other int: "+i // <4>
case d: Double => "a double: "+x // <5>
case "one" => "string one" // <6>
case s: String => "other string: "+s // <7>
case unexpected => "unexpected value: " + unexpected // <8>
}
println(str) // <9>
}
上例中最后一个 case 语句没有类型标注, 可以匹配任何类型的值, 相当与其他语言中的 default 。 匹配成功的 case 语句 => 后的部分为 match 语句的返回值, match 语句返回值的类型为所有 case 子句返回值类型的最小父类型。 因为变量 x 在所有子句中可用, 所以可以省略 case 子句中的变量, 使用 _ 替代变量名, 只需在后面加上类型标注。
for {
x <- Seq(1, 2, 2.7, "one", "two", 'four)
} {
val str = x match {
case 1 => "int 1"
case _: Int => "other int: "+x
case _: Double => "a double: "+x
case "one" => "string one"
case _: String => "other string: "+x
case _ => "unexpected value: " + x
}
println(str)
}
除了偏函数, 所有 match 语句都必须完全覆盖所有输入, 一般最后一个语句使用
case _ => {...}匹配所有情况。
在 case 语句中使用已有的变量来匹配的时候需要给变量加上反引号, 否则 case 语句会忽略之前的变量, 而将其作为一个能匹配所有的值的子句。
val y = 1
case y => "int 1" //不等效于 case 1 => “int 1”, 而是匹配所有值
case `y` => "int 1" //等效于 case 1 => {...}
case 子句可以包含或逻辑, 比如 case _: Int | _: Double => {...} 。
序列的匹配
Seq 是具体集合类型的父类型, 这些集合支持以确定顺序遍历其元素, 如 List 和 Vector 。
def seqToString[T](seq: Seq[T]): String = seq match {
case head +: tail => s"$head +: " + seqToString(tail)
case Nil => "Nil"
}
元组的匹配
val langs = Seq(
("Scala", "Martin", "Odersky"),
("Clojure", "Rich", "Hickey"),
("Lisp", "John", "McCarthy"))
for (tuple <- langs) {
tuple match {
case ("Scala", _, _) => println("Found Scala")
case (lang, first, last) =>
println(s"Found other language: $lang ($first, $last)")
}
}
case 中的 guard 语句
for (i <- Seq(1,2,3,4)) {
i match {
case _ if i%2 == 0 => println(s"even: $i")
case _ => println(s"odd: $i")
}
}
给匹配语句加一些限制条件。
case 类的匹配
case class Address(street: String, city: String, country: String)
case class Person(name: String, age: Int, address: Address)
val alice = Person("Alice", 25, Address("1 Scala Lane", "Chicago", "USA"))
val bob = Person("Bob", 29, Address("2 Java Ave.", "Miami", "USA"))
val charlie = Person("Charlie", 32, Address("3 Python Ct.", "Boston", "USA"))
for (person <- Seq(alice, bob, charlie)) {
person match {
case Person("Alice", 25, Address(_, "Chicago", _)) => println("Hi Alice!")
case Person("Bob", 29, Address("2 Java Ave.", "Miami", "USA")) =>
println("Hi Bob!")
case Person(name, age, _) =>
println(s"Who are you, $age year-old person named $name?")
}
}
注意第一个 case 语句, 在 case 语句中可以进行深度匹配。 先进行了 Person 的提取, 然后对里面的 Address 进行了提取。
unapply 方法
通过上面的几个示例, 已经发现了模式对任意类型对象匹配强大的能力, 但是这种强大的能力是怎么做到的呢? 在之前我们了解到 case 类中有一个 apply 方法进行构造, 跟单例对象中的 apply 方法用于构造一样。 所有基于对称的思想, 存在一个叫 unapply 的方法用于解构对象, 这个方法用于将对象内部的状态提取出来, 和 apply 的作用完全相反。 当遇到下面形式的类型匹配表达式的时候, 该方法就会被调用。
person match {
case Person(name, 25, Address(_, "Chicago", _)) ...
}
遇见以上 case 语句时, 实际是调用了 Person 单例对象的 unapply 方法对 person 对象内部状态的提取, 并进行相关匹配与case语句相关变量的赋值。 unapply 方法的签名为:
def unapply(object: ObjectType): Option[TupleN[...]] = ...
N 为提取值的个数, 编译器提取值后依次与 case 语句进行比对, 不匹配就会返回 None 对 case 子句进行否定, 然后比对下一个 case 子句。 匹配后才进行相关的变量赋值。
为了性能上的提升, 从 Scala 2.11.1 开始放松了对 unapply 方法必须返回 Option 的限制, 只要返回的类型中有以下方法就可:
def isEmpty: Boolean def get: T
上面几例是通过单例对象的 unapply 方法对相应对象内部状态进行提取, 接下来我们看看对序列的提取。 scala 在库中定义了一个名为 +: 特殊的单例对象, 在这个对象中有个 unapply 方法, 我们可以简单的理解这个方法的类型签名为 (真实情况要比这复制):
object +: {
def unapply[T, Coll](collection: Coll): Option[(T, Coll)] = {...}
}
所以对于 Seq 我们可以使用如下的匹配方式:
def seqToString[T](seq: Seq[T]): String = seq match {
case +:(head, tail) => s"$head +: " + seqToString(tail)
case Nil => "Nil"
}
等等, 这怎么与上文中序列的匹配不同呢?! 这其实是 scala 编译器的一个语法糖: 包含两个类型参数的类型可以写为中缀表达式, 例如下面的用法。
case class With[A, B](a: A, b: B)
val w1: With[String, Int] = With("Foo", 1)
val w2: String With Int = With("Bar", 2)
Seq(w1, w2) foreach { w =>
w match {
case s With i => {...}
case _ => {...}
}
}
List 有一个类似的对象 :: , 如果逆序处理序列, 有一个 :+ 对象, 同样也有一个 :+ 方法在序列末尾追加元素。 注意区分一个是对象一个是方法,不要搞混淆。
unapplySeq 方法
Seq 伴随对象里还包含一个 unapplySeq 方法。 用于更加灵活的提取序列中不固定数量的值:
def windows[T](seq: Seq[T]): String = seq match {
case Seq(head1, head2, _*) =>
s"($head1, $head2), " + windows(seq.tail)
case Seq(head, _*) =>
s"($head, _), " + windows(seq.tail)
case Nil => "Nil"
}
不过我们仍然可以使用 +: 的方式进行匹配:
def windows2[T](seq: Seq[T]): String = seq match {
case head1 +: head2 +: tail => s"($head1, $head2), " + windows2(seq.tail)
case head +: tail => s"($head, _), " + windows2(tail)
case Nil => "Nil"
}
可变参数列表的匹配
使用可变参数定义 case 类时, 自动生成的提取器方法为 unapplySeq , 所以只能使用对应的提取方法匹配提取的值, 比如定义 case 类为:
case class WhereIn[T](columnName: String, val1: T, vals: T*)
那么自动生成的提取器方法为:
def unapplySeq[T](WhereIn[T]): Option[(String, T, Seq[T])]
匹配时最后一项必须要 _* , 比如 case WhereIn(col, v1, _*) => ..., 但是如果要获取最后的 Seq[T] 类型的值, 可以使用 @ 来获取, 在 Haskell 中这种写法叫做 AS 语法: case WhereIn(col, v1, vs @ _*) => ...
正则表达式的匹配
正则表达式可以很方便的从符号特定解构的字符串中提取数据:
val BookExtractorRE = """Book: title=([^,]+),\s+author=(.+)""".r
val MagazineExtractorRE = """Magazine: title=([^,]+),\s+issue=(.+)""".r
val catalog = Seq(
"Book: title=Programming Scala Second Edition, author=Dean Wampler",
"Magazine: title=The New Yorker, issue=January 2014",
"Unknown: text=Who put this here??"
)
for (item <- catalog) {
item match {
case BookExtractorRE(title, author) =>
println(s"""Book "$title", written by $author""")
case MagazineExtractorRE(title, issue) =>
println(s"""Magazine "$title", issue $issue""")
case entry => println(s"Unrecognized entry: $entry")
}
}
case 语句的变量绑定
在对象提取类值,可以将值绑定到对应的变量, 也可以使用 AS 语法整体绑定, 比如修改之前的例子:
case class Address(street: String, city: String, country: String)
case class Person(name: String, age: Int, address: Address)
val alice = Person("Alice", 25, Address("1 Scala Lane", "Chicago", "USA"))
val bob = Person("Bob", 29, Address("2 Java Ave.", "Miami", "USA"))
val charlie = Person("Charlie", 32, Address("3 Python Ct.", "Boston", "USA"))
for (person <- Seq(alice, bob, charlie)) {
person match {
case p @ Person("Alice", 25, address) => println(s"Hi Alice! $p")
case p @ Person("Bob", 29, a @ Address(street, city, country)) =>
println(s"Hi ${p.name}! age ${p.age}, in ${a.city}")
case p @ Person(name, age, _) =>
println(s"Who are you, $age year-old person named $name? $p")
}
}
类型匹配
你或许会认为如下代码能按照你预计的想法运行:
for {
x <- Seq(List(5.5,5.6,5.7), List("a", "b"))
} yield (x match {
case seqd: Seq[Double] => ("seq double", seqd)
case seqs: Seq[String] => ("seq string", seqs)
case _ => ("unknown!", x)
})
但其实并不能如你所愿!!! 原因就是 scala 主要运行与 JVM 中, JVM 会有 类型擦除 , 这是一个历史遗留问题, 这导致 Seq[Double] 与 Seq[String] 不能区分, 第一个 Seq[Double] 将匹配任何 Seq 类型。
一个不太美观的解决方式是进行嵌套匹配:
def doSeqMatch[T](seq: Seq[T]): String = seq match {
case Nil => "Nothing"
case head +: _ => head match {
case _ : Double => "Double"
case _ : String => "String"
case _ => "Unmatched seq element"
}
}
封闭继承层级与全覆盖匹配
模式匹配的最后一个 case 子句一般都使用 case _ => ... 处理额外的情况, 但是如果匹配的类型是一个使用 sealed 定义的类型, 而且在 case 语句中处理了所有的子类的情况, 那么末尾就没有必要使用 _ 来处理额外的情况, 因为 sealed 关键字使不可能有其它的情况出现, 这种情况叫做全覆盖匹配。 如果对没有 seaded 关键字的类型进行匹配, 那么就不能使用全覆盖匹配, 因为 API 的使用者可以自由的对类进行派生, match 子句不能预测用户的派生, 就必须使用 _ 给出额外值的默认处理。 示例代码
模式匹配的其他用法
模式匹配这一强大的特性不仅局限于 case 语句, 定义变量也可以运用, 包括 for 中的变量定义。
case class Address(street: String, city: String, country: String)
case class Person(name: String, age: Int, address: Address)
val Person(name, age, Address(_, city, )) =
Person("Alice", 25, Address("1 Scala Lane", "Chicago", "USA"))
val h1 +: h2 +: tail = Vector(1,2,3,4,5)
val maybedogs = List(Some("Bob"), None, Some("Tom"), None, Some("putty"))
val dogs2 = for {
Some(dog) <- maybedogs
} yield {
dog
} //dog = List("Bob", "Tom", "putty")
隐式详解
隐式是 scala 中独一无二、强大但有争议的特性, 其可以减少代码, 向已有类型中注入新方法, 还有一系列工具用于构建 DSL 。
隐式参数
如果一个环境中的一个对象被多次作为参数使用, 那么为了减少样本代码, 可以使用 implicit 关键字将对象声明为隐式对象, 使用该对象的方法或函数的参数声明为隐式参数, 那么调用函数的时候就不必去显示的使用对象, 可以忽略该参数, 编译器会自动使用环境中的对象作为参数。 比如计算税后收入, 当税率固定, 那么可以将税率声明为隐式对象。
object Main {
def main(args: Array[String]): Unit = {
implicit val rate: Float = 0.05F
def calcTax(amount: Float)(implicit rate: Float): Float = amount * rate
val amount = 100F
println(s"Tax on $amount = ${calcTax(amount)}")
}
}
有时候单独的对象不能处理一些复杂的情况, 我们可以使用下面的方式:
object Main {
def main(args: Array[String]): Unit = {
case class ComplicatedSalesTaxData(
baseRate: Float,
isTaxHoliday: Boolean,
storeId: Int)
implicit def rate(implicit cstd: ComplicatedSalesTaxData): Float =
if (cstd.isTaxHoliday) 0.0F
else cstd.baseRate + extraTaxRateForStore(cstd.storeId)
implicit val myStore = ComplicatedSalesTaxData(0.06F, false, 1010)
val amount = 100F
println(s"Tax on $amount = ${calcTax(amount)}")
}
}
calcTax(amount) 先使用 rate , 这儿的 rate 是一个返回 Float 的方法, rate 使用 myStore 隐式参数。
隐式参数适用场景
执行上下文
例如在前文中介绍的 Future 对象, 其 apply 方法的声明为:
def apply[T](body: => T)(implicit executor: ExecutionContext): Future[T]
使用的时候如果没指定特别的 ExecutionContext 对象, 需要引入全局默认值: import scala.concurrent.ExecutionContext.Implicits.global
功能控制
权限控制, 使用全局隐式变量 session 记录用户登录状态, 方法对不同状态表现不同的行为(以下代码不可运行):
def createMenu(implicit session: Session): Menu = {
val accountItems = if (session.loggedin()) List(view, edit)
else List(loginItem)
}
限定可用实例
隐式证据
看下列示例:
val l1 = List(1,2,3,4)
val l2 = List("one"->1, "two"->2, "three"->3)
l1.toMap // error: Cannot prove that Int <:< (T, U).
l2.toMap // res0: Map[String, Int] = Map(one->1, two->2, three->3)
在 toMap 的定义中:
trait TraversableOnce[+A] extends ... {
...
def toMap[T,U](implicit ev: <:<[A, (T, U)]): Map[T,U]
}
ev 便是证据, 证明 A 可以转化为 (T, U) 。
绕开类型擦除带来的限制
由于 JVM 的类型擦除, 下面这段代码将不能按照我们的意愿运行:
object C {
def m(seq: Seq[Int]): Unit = ???
def m(seq: Seq[String]): Unit = ???
} // error: double definition: method m ...
我们可以用隐式参数来消除这种方法二义性:
object M {
implicit object IntMarker
implicit object StringMarker
def m(seq: Seq[Int])(implicit i: IntMarker.type): Unit =
println(s"Seq[Int]: $seq")
def m(seq: Seq[String])(implicit s: StringMarker.type): Unit =
println(s"Seq[String]: $seq")
}
单例对象的类型为 类型名.type
改善报错信息
虚类型
虚类型表明我们只关注类型, 而不关心类型的值, 这对于某些必须按照特定工作流执行的运算提供来类型检查的功能, 比如计算税后工资, 先减去保险的部分, 然后减去养老账户的部分, 然后减去扣税, 最后减去最后税, 如果这个过程没按顺序执行, 就会产生错误的计算结果, 但是每一步计算的类型都是一个相同的状态信息, 我们只有人工的检查这个过程是否有误, 我们想把这个过程丢给编译器进行检查, 于是就引入来虚类型来帮忙实现:
sealed trait Start
sealed trait Step1
sealed trait Step2
sealed trait Step3
sealed trait Final
case class Employee(
name: String,
annualSalary: Float,
taxRate: Float,
insurancePremiumsPerPayPeriod: Float,
_401kDeductionRate: Float,
postTaxDeductions: Float)
case class Pay[Step](employee: Employee, netPay: Float)
object Payroll {
def start(employee: Employee): Pay[Start] =
Pay[PreTaxDeductions](employee, employee.annualSalary / 26.0F)
def minusInsurance(pay: Pay[Start]): Pay[Step1] = {
val newNet = pay.netPay - pay.employee.insurancePremiumsPerPayPeriod
pay.copy(netPay = newNet)
}
def minus401k(pay: Pay[Step1]): Pay[Step2] = {
val newNet = pay.netPay - (pay.employee._401kDeductionRate * pay.netPay)
pay.copy(netPay = newNet)
}
def minusTax(pay: Pay[Step2]): Pay[Step3] = {
val newNet = pay.netPay - (pay.employee.taxRate * pay.netPay)
pay.copy(netPay = newNet)
}
def minusFinalDeductions(pay: Pay[Step3]): Pay[Final] = {
val newNet = pay.netPay - pay.employee.postTaxDeductions
pay copy (netPay = newNet)
}
}
object CalculatePayroll {
def main(args: Array[String]) = {
val e = Employee("Buck Trends", 100000.0F, 0.25F, 200F, 0.10F, 0.05F)
val pay1 = Payroll.start(e)
// 401K and insurance can be calculated in either order.
val pay2 = Payroll minus401k pay1
val pay3 = Payroll minusInsurance pay2
val pay4 = Payroll minusTax pay3
val pay = Payroll minusFinalDeductions pay4
}
}
上面的示例我们通过引入虚类型来限制执行过程。 如果没有按照规定的过程计算, 编译器会检查出来错误。
隐式参数遵循的规则
- 只允许最后一个参数列表出现隐式参数
- implicit 关键字必须出现在列表的最左边, 且只能出现一次, 且本列表 implicit 关键字后的参数都是隐式的。
隐式转换
我们经常使用 -> 构造二元组, 比如 1 -> "one" 、 "one" -> 1 等, 但是这种写法并不是字面量写法, -> 其实是一个方法, 但是我们希望对任何的对象都可以使用 -> 方法, 去改造所有类型的定义添加一个方法的方式显然不行, scala 提供了一种给对象注入方法的手段, 那就是隐式转换, 这种转换通过 隐式类 实现, 比如 scala 在 Predef 对象中定义来隐式类来注入 -> 方法:
implicit final class ArrowAssoc[A](val arrow_start: A){
def ->[B](arrow_end: B): Tuple2[A,B] = Tuple2(arrow_start, arrow_end)
}
隐式类起作用的时候, 调用方法的对象被当做隐式类的参数构造新对象, 然后在新对象上调用对应的方法。 以下是编译器进行查找和使用转换方法时的查询规则:
- 调用的对象和方法成功通过了组合类型检查, 那么类型转换不会执行。
- 编译器只会考虑使用了 implicit 关键字的类和方法。
- 编译器只考虑当前作用域内的隐式类, 隐式方法, 以及目标类型的伴生对象中定义的隐式方法。 这种特性给 scala 类型类模式提供类很好的支持。
- 隐式方法无法串行处理。
- 假如当前适用多条转换方法, 那么不会执行操作。
表达式问题
隐式转换可以通过不修改源码的情况下为所有类型添加新方法。 面向对象编程通过 子类型化 的方式实现这一功能, 但是这一技术是有弊端的: 什么时候我们在父类中定义方法, 什么时候声明成抽象的方法, 如果使用不当, 这些定义在父类中的方法就会变成子类加载的负担。
类型类模式
类型类最先被 Haskell 引入, 之后 Scala 也实现了类型类模式。 在 scala 中我们可以使用隐式转换为类型注入新的方法, 也可以使用类型类模式。 下面这个例子简要描述类类型类的用法, 点击这儿更加详细了解:
case class Address(street: String, city: String)
case class Person(name: String, address: Address)
trait ToJSON {
def toJSON(level: Int = 0): String
val INDENTATION = " "
def indentation(level: Int = 0): (String,String) =
(INDENTATION * level, INDENTATION * (level+1))
}
implicit class AddressToJSON(address: Address) extends ToJSON {
def toJSON(level: Int = 0): String = {
val (outdent, indent) = indentation(level)
s"""{
|${indent}"street": "${address.street}",
|${indent}"city": "${address.city}"
|$outdent}""".stripMargin
}
}
implicit class PersonToJSON(person: Person) extends ToJSON {
def toJSON(level: Int = 0): String = {
val (outdent, indent) = indentation(level)
s"""{
|${indent}"name": "${person.name}",
|${indent}"address": ${person.address.toJSON(level + 1)}
|$outdent}""".stripMargin
}
}
val a = Address("1 Scala Lane", "Anytown")
val p = Person("Buck Trends", a)
println(a.toJSON())
println(p.toJSON())
类型类式 scala 中很重要的一种思想, 请仔细阅读相关资料, 深入了解!
隐式所导致的技术问题
大量使用隐式可能会使代码变得难以理解, 并且编译器在处理隐式的时候会消耗额外的时间, 大量的隐式会使代码编译变得缓慢。 从代码运行角度来说隐式也会使代码变缓慢, 封装类会引入额外的开销。 顺便说一句, scala 中的 值类型 就是为了消除封装带来的额外开销。
隐式解析规则
scala 会解析无须输入路径前缀的类型兼容隐式值。
scala 内置的各种各样的隐式
合理使用
scala 函数式编程
什么是函数式编程
数学中的函数
不可变变量
scala 中的函数式编程
匿名函数、 Lambda 与闭包
内部与外部的纯粹性
递归
部分应用函数与偏函数
Curry 化与函数的其它转换
函数式编程的数据结构
Seq
Map
Set
foreach map filter fold reduce
foreach
map
filter
fold reduce
[fold|reduce][Left|Right]
组合器
关于复制
深入学习 for 推导式
scala 面向对象编程
特质 Trait
scala 对象系统
scala 集合库
可见性规则
scala 类型系统
高级函数式编程
并发工具
scala 与大数据
scala 动态调用
深入 DSL
与 java 互操作
应用程序设计
元编程: 宏与反射
欢迎加入 scala 成都技术交流群